
The previous articles on isolation levels were using pessimistic locking. Two further isolation levels exist that use optimistic locking and are row-versioning based.
Snapshot Isolation
With snapshot isolation level no locks are placed upon the data when it is read and transactions that write data don’t block snapshot isolation transactions from reading data. Instead, when the first statement within a transaction is started, a version of the data it requires is stored in tempdb along with a sequence number. It uses this sequence number to control access to the consistent version of the data for that transaction.
Snapshot isolation, like the serializable isolation level, does not allow dirty reads, lost updates, phantom rows or nonrepeatable reads. However, snapshot isolation does not use locks to achieve this. Instead it has a consistent version of the data, taken at the start of the transaction and if an update to this data clashes with an update performed elsewhere then the transaction is rolled back.
To set snapshot isolation requires setting a database level property.
ALTER DATABASE IsolationLevels SET ALLOW_SNAPSHOT_ISOLATION ON;
This enables the row versioning mechanism within the database. Versioned rows will be stored even if the isolation level specified for the query is pessimistic. However, you still need to specify the snapshot isolation level for the query in order to use versioned data.
Example 1 – updating a row
Using the same table used in the serializable example, transaction 1 will use read committed isolation to read and update the value with one row.
At the same time a snapshot isolation level transaction will select the same row and attempt an update.
In transaction 1

Note the absence of a COMMIT or ROLLBACK at this point, locking this row. It will show the updated value of 2, for the column ‘Test_Value’.
In transaction 2
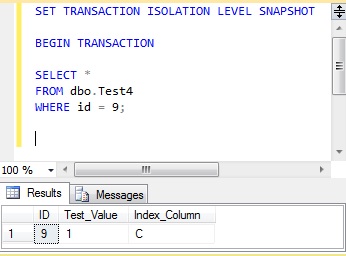
Using snapshot isolation, this shows the value of 1 for ‘Test_Value’, because at the time this transaction started the update in transaction 1 had not been committed.
If we now COMMIT transaction one and then re-run the SELECT query within transaction 2 the value is unchanged.

This transaction is still reading the data from the version store, to keep the view of this transaction consistent.
Because the row with ‘ID’ of 9 has now been updated elsewhere, an attempt by transaction 2 to update this row will result in an error message and a rollback of the transaction.

The entire error message is
Msg 3960, Level 16, State 2, Line 1
Snapshot isolation transaction aborted due to update conflict. You cannot use snapshot isolation to access table ‘dbo.Test4’ directly or indirectly in database ‘IsolationLevels’ to update, delete, or insert the row that has been modified or deleted by another transaction. Retry the transaction or change the isolation level for the update/delete statement.
Of course, re-running transaction 2 now will show the updated value and an update will be allowed because nothing else will be in the process of updating it.

Example 2 – inserting a row
Transaction 1 selects the first few rows, transaction 2 inserts a row within the same range that transaction 1 is using and transaction 3 then selects the first few rows.
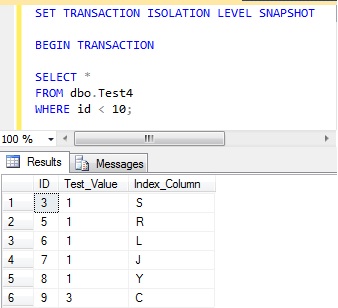
Transaction one selects all rows where the ‘ID’ column has a value less than 10, and retrieves 6 rows.
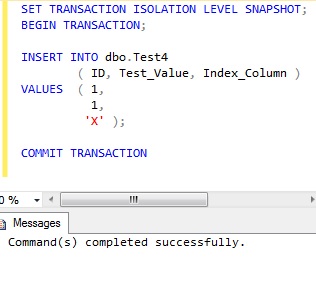
Transaction 2 inserts a new row, with an ‘ID’ value of 1, which should make it within the range of the transaction 1 query.
Re-run the SELECT query within transaction 1 and the results are unchanged – it is using the data from the version store.

Repeat this query in transaction 3 and the extra row is also selected, as it is using the latest version of the data.
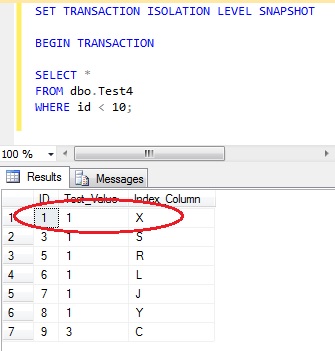
Unlike the serializable isolation level it has been possible to insert a row within the range that transaction 1 had selected, but transaction 1 will never show this new row. It will keep a consistent version of the data until the transaction has completed or rolled back.
Example 3 – deleting a row
As expected, the behaviour is the same as with the insertion – transaction 1 will read a range of data.
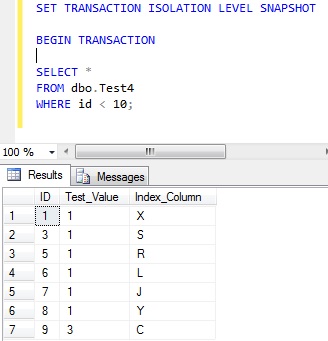
Transaction 2 will delete one of the rows that transaction 1 had selected.

Repeating the select within transaction 1 will give the same results, even though transaction 2 has since removed a row.
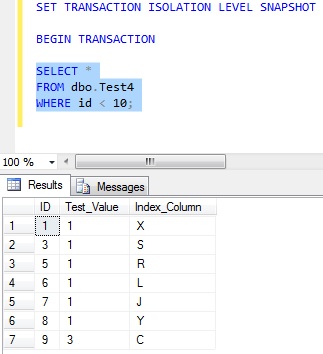
Executing transaction 3 after the deletion will show the latest data.

The Overhead
Setting the database to ALLOW_SNAPSHOT_ISOLATION starts the generation of row versions, even for transactions that do not use snapshot isolation. This command will not complete until all currently executing transactions have completed, so may take a while to return (https://msdn.microsoft.com/en-us/library/bb522682.aspx) .
Versioning adds 14 bytes to every row of the database as they are accessed, so it is essential to take this additional storage into account.
The versioned data is stored in tempdb, so this can grow by a large amount for databases that are heavily used. In addition, this store is a linked list of related versions, so transactions may have to traverse a long linked list if there are transactions that have been open for a long time. This of course adds to the processing time of a transaction. There is a clean-up process that runs frequently, to clear this list but it may not be able to remove all entries, depending upon how heavily the database is being used.
A range of DMVs and functions are available to monitor the behaviour of versioning within a database – https://msdn.microsoft.com/en-us/library/ms178621.aspx but if the version store is large these can also take a while to process.
Conclusion
Snapshot isolation is not suitable for databases where data updates are frequent, as it will have the potential to raise a large number of conflicts. It is more suited to databases that are mainly read, with data inserted or deleted but few updates.
