Seriously, you shouldn’t get excited about a function, command or whatever. It’s just a tool for a job and not the reason you live.
But then in SQL 2005 Row_Number was introduced.
I didn’t do a great deal of work with SQL 2000 but I do remember the fun to be had when trying to find something as simple as the maximum or minimum value for something for a particular person or product. Another common problem – trying to remove duplicated data was certainly more fun than should be legally allowed. Subqueries abound and T-SQL code tied itself into nice little knots to achieve something that shouldn’t really be that difficult.
So lets start with a very basic example, just adding a sequential number the rows of a table:
CREATE TABLE #test1(
TestID INT);
INSERT INTO #test1
( TestID )
VALUES (3),
(4),
(7),
(9),
(15),
(22);
Nothing exciting in that. If we now SELECT from that and add a ‘count’ that changes every time TestID changes:
SELECT TestID,
ROW_NUMBER() OVER (ORDER BY TestID)
FROM #test1;
The result has the TestID followed by the Row_Number result:

Not a wild amount of use in this case but supposing we had several rows with the same ID and different values alongside, and we want to select the row for each ID that has the highest amount stored against it.
CREATE TABLE #test2(
TestID INT,
TestAmount INT
);
INSERT INTO #test2
( TestID, TestAmount )
VALUES ( 1, 100),
( 1, 101),
( 1, 95),
( 2, 15),
( 3, 12),
( 3, 1),
( 4, 800),
( 4, 123),
( 4, 192),
( 4, 55);
Now look at the result of a Row_Number query where I’ve ordered it by the TestAmount and partitioned it by the TestID. The PARTITION BY effectively tells the function how to seperate the data, in this case count within the same value for TestID. When TestID changes the count will reset.
SELECT TestID, TestAmount, ROW_NUMBER() OVER (PARTITION BY TestID ORDER BY TestAmount DESC) AS [Sequence] FROM #test2;
The result of this query is:

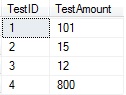
From this you can see that the highest value has been allocated a Sequence value of 1. Knowing this it is easy to filter on that value.
Combine it with a CTE and you can select the rows with the highest value:
WITH SortedAmounts AS ( SELECT TestID, TestAmount, ROW_NUMBER() OVER (PARTITION BY TestID ORDER BY TestAmount DESC) AS [Sequence] FROM #test2 ) SELECT TestID, TestAmount FROM SortedAmounts WHERE Sequence = 1;
With this result: