
Generally, when somebody posts a query using the NOLOCK hint, there are a variety of warnings about dirty reads, phantom reads and double-reading (due to page splits).
The dirty read example is common and tends to be the main example used to demonstrate what to watch out for with NOLOCK, but I’ve never seen an example of double-reading. So, I thought I’d try and see how much of an issue such a thing can be. It certainly sounds plausible, but is it a ‘one in a million’ chance, or is it a Terry Pratchett ‘one in a million’ chance – where it is pretty much guaranteed to happen?
So, create a database for this testing and then create a table within:
CREATE TABLE [dbo].[Test1]( [ID] [int] IDENTITY(1,1) NOT NULL, [Test_Description] [nvarchar](max) NULL, PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 100) ON [PRIMARY] ) ON [PRIMARY] GO
A very simple table – an Identity column and a text column. The important part is that I’ve specified a Fill Factor of 100 for the Clustered Index, meaning there is no space for expansion of the data in the current location. Therefore, if I increase the contents of the ‘Test_Description’ column it should force a page-spilt, because the data won’t fit back where it was originally stored.
I then generate 500,000 rows with a simple integer id and the entry ‘TEST’ in the ‘Test_Description’ column.
In one window of SSMS I now set up a query to update this column on every row. For text-based test data I tend to use a text file of ‘War and Peace’, from Project Gutenberg. For this test I just use the first paragraph.
In another window I set up a query to return every row from the same table, specifying ‘READ UNCOMMITTED’ isolation level.
Once prepared I run the two queries together:


The update has returned a count of 500,000, which matches the number or rows I placed into that table.
However, the select has returned a count of 586,078. Considerably higher than the number of rows within that table. In addition, it can be seen within the results that I’m retrieving a mixture of updated and non-updated rows.
Exporting the results to a csv file and then into Excel, I can sort the results and see a large number of duplicates (based on the ID column):
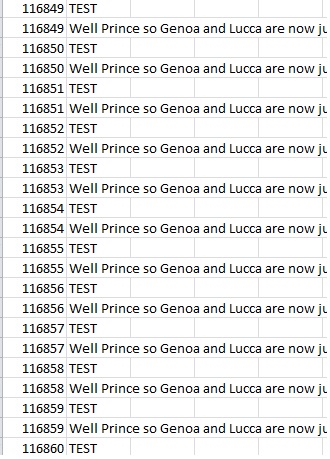
The Select found the rows before they were updated, and then again when the page split had moved the data, retrieving the row twice.
If I leave the select query to run once the update has completed, I get 500,000 rows – all updated.
This was a relatively easy test to set up, and has been consistent in the fact that it has duplicated a large number of rows every time. Of course, specifying a fill factor of 100 would pretty much guarantee a page split somewhere, but in the day-to-day operations of most databases, pages will become full and splits will happen eventually. So the scale of the issue might not be as large as the example I’ve created, but the underlying issue may still be present.
Obviously, if this was something more important that a short piece of text (financial data, for example) then the results derived from this query would be wildly inaccurate.
