
In a previous article I demonstrated how use of READUNCOMMITTED (or the NOLOCK hint) can result in erroneous data, due to page splits. Examples abound of the more common issue with this isolation level, which occur when reading a row that is being updated in another transaction and then rolled back. These so-called ‘dirty reads’ cannot happen with the default isolation level of READ COMMITTED.
However, it is still possible to alter data within a table that is being read with READ COMMITTED, so that the results of that transaction do not reflect the actual state of the data when the transaction has completed.
For this demonstration I’ll create a table that contains an ID column and an integer column, with a clustered index on the ‘ID’ column.
CREATE TABLE [dbo].[Test2]( [ID] INT NOT NULL, [Test_Value] INT NOT NULL, PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
For reasons that will become apparent I’ll start the ID from 10, incremented by 1 for each row and store 1 in ‘Test_Value’ against each row.
With nothing else executing against that table there are 5,000,000 rows and the sum of ‘Test_Value’ is 5,000,000:
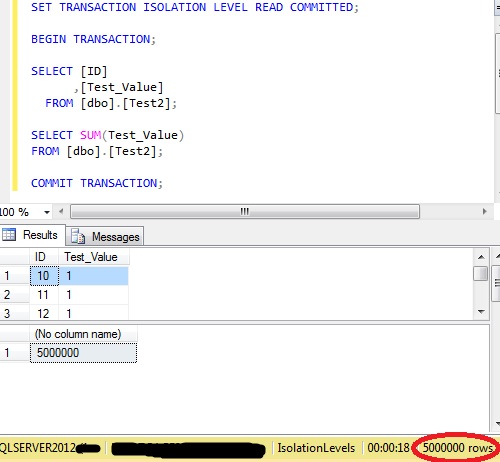
The two queries within this transaction are looking at the same data.
Now I will repeat this query, and in a separate tab I will update the row with ID of 10 to move it to the end of the index, as soon as the first query has started:
UPDATE dbo.Test2 SET id = id + 6000000 WHERE id = 10;
The results for this an extra row in the first SELECT:
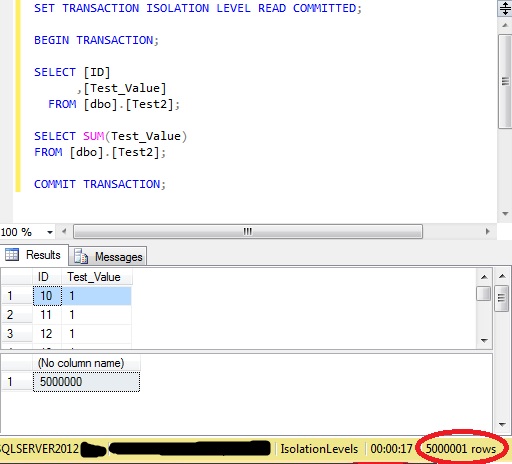
And if I scroll to the end of that result, the row that was shown with an ID of 10 is also shown with an ID of 6000010.

So, the first SELECT query has looked at the same row, before and after it was moved. However, the second SELECT query, because it read the data after all of the updating, has returned the correct information.
Resetting the data, it is also possible to ‘lose’ a row, when a row at the end of the index is moved to the start of the index, during the first SELECT.
This time, the second query is:
UPDATE dbo.Test2 SET id = 9 WHERE id = 5000009;
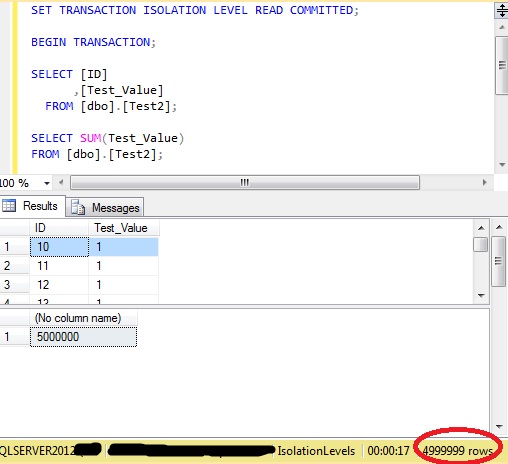
This time, the row with an ID of 9 is not shown in the results, because the update moved it from the end of the index to the beginning of the index after the SELECT had read the beginning of the index but before it had reached the end of the index.
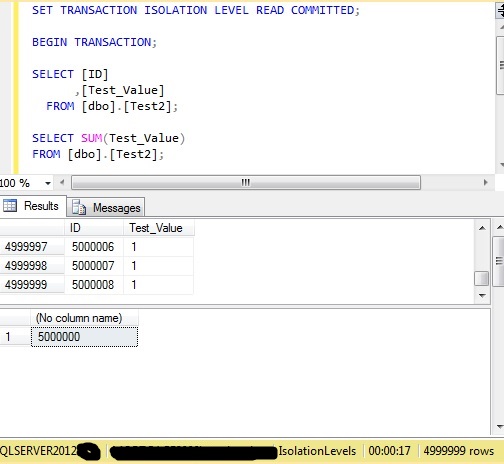
The sum shows the correct results because the update had completed before the second select started.
A Smaller Demonstration
In the examples shown there were five million rows, but what about smaller tables?
Consider a far smaller table, which is accessed by three processes. One is simply reading the whole table (with READ COMMITTED Isolation Level). At the same time a second process has locked a row, because it is updating it. In addition, a third process is updating data and in the process is moving the row to another position within the index.
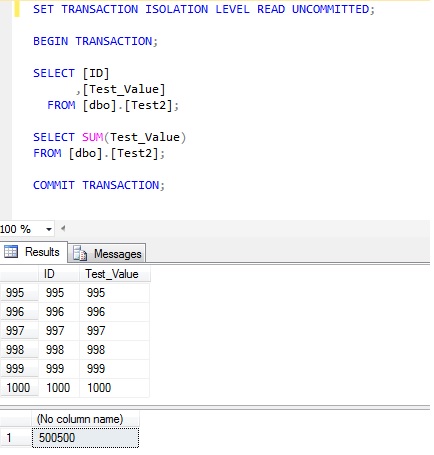
Firstly – the data before it is interfered with shows one thousand rows that SUM to 500500:
In a separate tab run the following command:
BEGIN TRANSACTION; UPDATE dbo.Test2 SET Test_Value = 1000 WHERE id = 50;
Notice that there is no ‘COMMIT’ or ‘ROLLBACK’. This will lock row 50.
Now run the initial command, with the two SELECT statements. This will be blocked by the update, because Row 50 is locked. READ UNCOMMITTED would use this (as yet uncommitted) Test_Value and continue. READ COMMITTED will not, and is therefore blocked.
In a third window:
BEGIN TRANSACTION; UPDATE dbo.Test2 SET ID = 1001 WHERE ID = 10; COMMIT TRANSACTION
This moved Row 10, which had already been read, and placed it at the end of the index.
Now ROLLBACK the update to row 50, this will allow the blocked process to continue.
The SELECT command has now completed, but the data for row 10 now also appears as row 1001 – the same data shown twice:
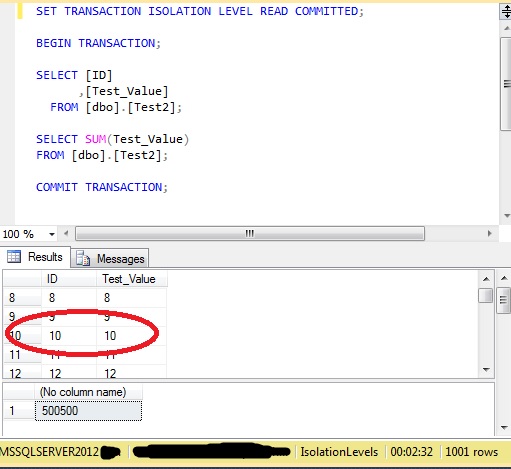

Of course, if the SELECT was also running a SUM or suchlike, the results would be incorrect in each of these examples.
So what is happening?
READ COMMITED obtains shared locks on the rows or pages as it requires them, but releases these locks as soon as it has read the locked data.
Therefore, it is possible to update, delete or insert rows where the query has already processed that area of the table, and to do the same in the part of the table that the query has yet to process. What is guaranteed with READ COMMITTED is that you can’t have dirty reads, but that’s pretty much it.
The fact that I placed the two queries within a Transaction also made no difference. The second query always saw the ‘true’ picture of the data because the manipulations had completed by that point.
I’ve frequently seen statements where people have claimed that to get a ‘true’ picture of the data that the default READ COMMITTED isolation level should be used. This clearly is a misunderstanding of how this process works, and one that I had to do a little bit of work to comprehend too.
