
In my previous article I showed how read committed would allow rows to be updated that it had already processed in a query, because it releases locks as soon as it has processed that row or page (depending upon the type of lock taken). A second query using the same criteria would then show different results from the first.
Repeatable read isolation level doesn’t allow this type of action to occur, because it retains the locks until the transaction has completed.
To demonstrate this, I have created a table with an ID column with a clustered index, a value (currently 1 for every row) and a CHAR(1) column with a letter in the range of A to Z, with a non-clustered index. In this table there are 26 million rows, basically to give me enough time to execute overlapping queries. In a real-world scenario the amount of data can be much less, but the issues still exist.
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO SET ANSI_PADDING ON GO CREATE TABLE [dbo].[Test4]( [ID] [int] NOT NULL, [Test_Value] [int] NOT NULL, [Index_Column] [char](1) NOT NULL, PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO SET ANSI_PADDING OFF GO SET ANSI_PADDING ON GO CREATE NONCLUSTERED INDEX [NC_Test4_Index_Column] ON [dbo].[Test4] ( [Index_Column] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
An initial query shows the values from the two queries – one showing the rows where ‘B’ is in the non-clustered index and the other showing the SUM of the ‘Test_Value’ column for the same criteria.
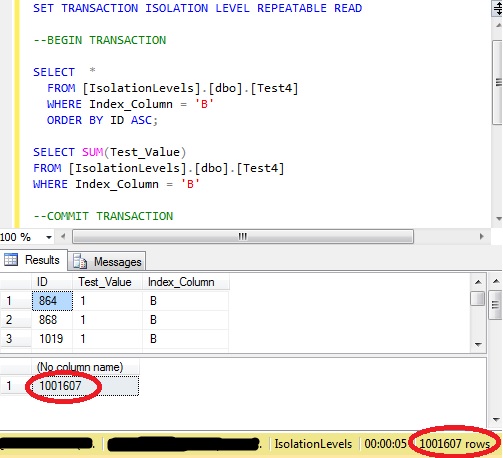
At this point the BEGIN/COMMIT TRANSACTION entries are commented out – meaning that the two queries are within their own separate transactions.
Repeating this set of commands and executing the following query in a separate window immediately after it starts:
UPDATE dbo.Test4 SET Test_Value = 2 WHERE ID = 864;
The results appear to show similar behaviour to the read committed – the row with ‘ID’ of 864 is shown in the first query as having a ‘Test_Value’ column of 1, not the 2 is was updated to and the second query has used the new value, because it was updated by the time that query started.
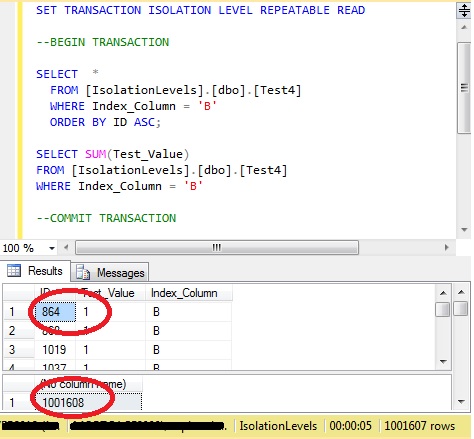
However, there is an important difference with this execution – the UPDATE command was blocked while the first query was executing.

In this case, SPID 79 is the SELECT Query and 82 is the UPDATE.
Reset the updated row back to 1, to return back to the ‘default’ results.
Now change the pair of queries, to execute inside one transaction and repeat the exercise.
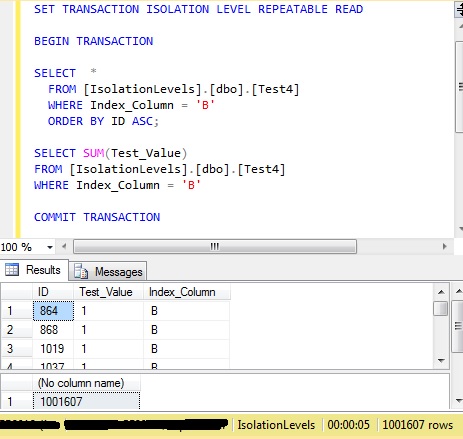
This time the update was blocked until both queries had completed, because they were inside the same transaction. With read committed isolation level this would not have made a difference.
So repeatable read isolation level blocks attempts to update or delete rows that are part of the query, but it still doesn’t prevent additional rows being added that will match the criteria but weren’t selected initially.
Adding qualifying data (Phantom Reads)
To demonstrate this, I have removed all but 100 of the rows that have ‘Index_Column’ with a value of ‘B’. A ten second delay has also been added between the two queries, in order to allow the timing of a second insert query to be executed. Both select statements are still within the same transaction, so the delay makes no difference to the execution of the commands – it just allows me to be consistent and repeatable with the actions.
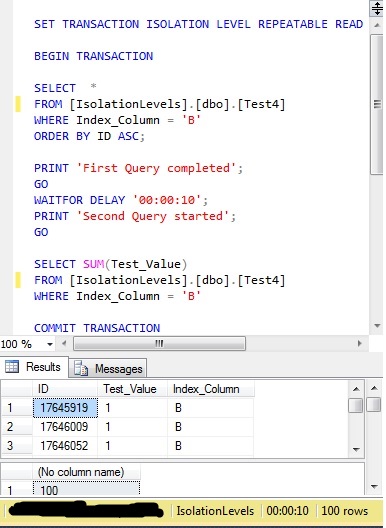
The first query returns 100 rows and the second a SUM of 100.
Running the main query and executing the following query during the 10-second delay, which will add a row to the start of the index.
INSERT INTO [dbo].[Test4]
([ID]
,[Test_Value]
,[Index_Column])
VALUES
(1
,1
,'B')
GO

Repeatable read has still allowed an insert within the transaction, so the second query has read more rows than the first. The additional row can be seen if the first SELECT is executed again.
Skipped Rows
Resetting the data and selecting the rows with a value on the ‘ID’ column < 21, produces 16 rows.

In a new window, a transaction is started that will potentially update the row with ‘ID’ = 10.
BEGIN TRANSACTION UPDATE dbo.Test4 SET Test_Value = 2 WHERE ID = 10;
Notice the absence of a ROLLBACK/COMMIT command, causing a block for the query that will read that area of the index.
Repeat the execution of the ‘WHERE id < 21’ query and it is blocked by the UPDATE query.
In a third window, update the row with ‘ID’ of 20, to move it to the start of the index.
UPDATE dbo.Test4 SET id = 3 WHERE id = 20;
When the command that has the missing ROLLBACK/COMMIT has a ROLLBACK TRANSACTION actioned against it, the blocked query will then complete.

The row with the ID of 20 is not shown, because it was moved to the ID of 3. However, it is not shown as 3 either, because the data had already read past that point when the SELECT was blocked.
Rerun this query and the moved row is shown, as one of 16 rows instead of 15.

As with read committed, it is still possible for the query to skip rows that have been moved within the index.
What repeatable read has removed is the possibility that data already processed for a query will be updated before that transaction has completed.
And the price for this?
With the increasing level of isolation comes the increasing level of blocking – more transactions waiting for other transactions to release locks.
Also, a higher chance of the infamous error 1205, where a deadlock has occurred and SQL has decided one transaction is the victim, so rolls it back. As the consistency level of the data increases, so do the compromises with multi-process access to data.
