
Background
Recently I had to write an SSIS package that would import a series of csv files that had different numbers of columns within them. One file might have 15 columns, another 17 and another have something different again.
To add to the fun the first nine columns of all of these files are ‘fixed’ – we know what each column is for, as well as the last three. Yes, the last three columns have a known purpose but they could be columns 13, 14 and 15 or 15, 16 and 17 or suchlike, depending upon how many columns the file has.
Figure 1: CSV File with 14 columns

Figure 2: CSV file with 12 columns

In the following article I’m going to describe the process I went through to solve this problem. The source code, data and SSIS package used in this article (obviously, not the actual project and data I have used at my employ) will be included at the foot of the article.
Initial Investigations
Of course, this isn’t the first time somebody has had to import a file with an unknown number of columns, so a little time with search engines found a handful of people that had worked out their own solutions.
There appeared to be two types of solution to this task – BIML and C# code to edit the project.
BIML – I have never used BIML but from the examples I saw it looked like it could be used to create an SSIS project based upon actions taken when opening the first csv file. This would work if all of the files had the same number of columns but they don’t. So if the first file processed had 15 columns then it would create a project to process 15 columns. If the next file opened had 16 columns then it wouldn’t process that file correctly.
C# – Looking at the examples I found of the C# solution could have been worked to provide a solution I needed but with a certain amount of complexity I would rather avoid. It has been a few years since I’ve written any meaningful C# code and if I’m going to struggle with it what about any DBA that should follow in my footsteps (or myself in a few months’ time)?
Now what?
So, if I can’t (or won’t) use these two solutions, what can I do?
Several years ago I worked with the Technical Director of a company, one Joe Gylanders. When database theory was surfacing he was writing his own database engines, to understand and implement the concepts and had a way of simplifying issues that I was quite envious of (and entertained by). Just never ask him for documentation.
Once, when working with him to import some particularly horrendous customer data into a new system I had to admit defeat with the import process I was attempting to hammer into a decent shape. He asked me what I wanted to do with this data and I promptly told him what columns were related to product details, what columns should be related to sales, what columns should be related to location and why certain inconsistencies were making it so very difficult to work out what data needed to be split to which table, from within the import process.
His reply (paraphrased somewhat) was “No, you don’t need any of that. You need to get that data into the database. Once it’s in there we can slice and dice it any way we want. The priority is to get the data into the database.”
So, with that in mind – what do I really want? If I get each record from the csv file into a database even as one column, can I use that?
Of course I can.
What I would have would be one column with data in it, separated by commas. Could we split that data based on that information?
My regular prowling of the SQL Server Central website has meant that for quite some time I’ve been aware of the ‘DelimitedSplit8K’ table-valued function, created and updated by Jeff Moden and many others. Given a string and the delimiter within that string it returns a table containing each of delimited values as well as a number to show which element it is from within that string. Therefore, not only can I split the data into the individual elements, I can also identify the first nine entries and the last three – the ‘fixed’ columns.
Creating the Project
Create the test database and a ‘staging’ table that the data will initially be stored into. This first table will have one column that contains the entire csv row and another column that contains the name of the file it was extracted from (just because I like to do such things – I can backtrack to the original data if I need to).
Listing 1: Create database and first staging table
CREATE DATABASE ImportTest; GO USE [ImportTest] GO CREATE TABLE [dbo].[Staging_SingleColumn]( [id] [INT] IDENTITY(1,1) NOT NULL, [ImportData] [VARCHAR](MAX) NULL ) ON [PRIMARY] GO
Now we create a second staging table which will take the divided data.
Note that I’ve included additional columns to convert some columns from their character format to the required format for the final table. ‘SurveyDate’ will be a varchar column at this point but I want it as a date column. I could have just converted it ‘in flight’ but I prefer to have a ‘before and after’ picture of the transformation. That way, if there any issues I can see the original data in the staging table and what it was transformed to. I’ve done a similar thing for ‘UploadedAt’, ‘Rating1’, ‘Rating2’ and ‘Rating3’.
Because I only know what the first nine and last three columns will consistently be, I have catered for up to 12 additional columns between these two groupings, with ‘VariableCol1’ through to ‘VarialeCol12’.
Listing 2: Second staging table
USE [ImportTest] GO CREATE TABLE [dbo].[Staging]( [ID] [INT] IDENTITY(1,1) NOT NULL, [SerialNo] [INT] NOT NULL, [SurveyName] [VARCHAR](100) NULL, [AreaName] [VARCHAR](100) NULL, [PropertyCode] [VARCHAR](20) NULL, [Controller] [VARCHAR](100) NULL, [OfficeName] [VARCHAR](100) NULL, [SurveyDate] [VARCHAR](50) NULL, [SDate] [DATE] NULL, [UploadedAt] [VARCHAR](50) NULL, [UDate] [DATETIME] NULL, [DeviceType] [VARCHAR](100) NULL, [VariableCol1] [VARCHAR](200) NULL, [VariableCol2] [VARCHAR](200) NULL, [VariableCol3] [VARCHAR](200) NULL, [VariableCol4] [VARCHAR](200) NULL, [VariableCol5] [VARCHAR](200) NULL, [VariableCol6] [VARCHAR](200) NULL, [VariableCol7] [VARCHAR](200) NULL, [VariableCol8] [VARCHAR](200) NULL, [VariableCol9] [VARCHAR](200) NULL, [VariableCol10] [VARCHAR](200) NULL, [VariableCol11] [VARCHAR](200) NULL, [VariableCol12] [VARCHAR](200) NULL, [Rating1] [VARCHAR](50) NULL, [Rating1Dec] [DECIMAL](10, 2) NULL, [Rating2] [VARCHAR](50) NULL, [Rating2Dec] [DECIMAL](10, 2) NULL, [Rating3] [VARCHAR](50) NULL, [Rating3Dec] [DECIMAL](10, 2) NULL ) ON [PRIMARY] GO
Finally, the destination table:
Listing 3: Final destination table
USE [ImportTest] GO CREATE TABLE [dbo].[SurveyData]( [ID] [INT] IDENTITY(1,1) NOT NULL, [SerialNo] [BIGINT] NULL, [SurveyName] [VARCHAR](100) NULL, [AreaName] [VARCHAR](100) NULL, [PropertyCode] [VARCHAR](20) NULL, [Controller] [VARCHAR](100) NULL, [OfficeName] [VARCHAR](100) NULL, [SurveyDate] [DATE] NULL, [UploadedDateTime] [DATETIME] NULL, [DeviceType] [VARCHAR](100) NULL, [VariableCol1] [VARCHAR](200) NULL, [VariableCol2] [VARCHAR](200) NULL, [VariableCol3] [VARCHAR](200) NULL, [VariableCol4] [VARCHAR](200) NULL, [VariableCol5] [VARCHAR](200) NULL, [VariableCol6] [VARCHAR](200) NULL, [VariableCol7] [VARCHAR](200) NULL, [VariableCol8] [VARCHAR](200) NULL, [VariableCol9] [VARCHAR](200) NULL, [VariableCol10] [VARCHAR](200) NULL, [VariableCol11] [VARCHAR](200) NULL, [VariableCol12] [VARCHAR](200) NULL, [Rating1] [DECIMAL](10, 2) NULL, [Rating2] [DECIMAL](10, 2) NULL, [Rating3] [DECIMAL](10, 2) NULL ) ON [PRIMARY] GO
There are four phases to this project:
1. Get the data into a single-column table,
2. Split the data from the single-column table where individual columns can be stored,
3. Convert any data to more appropriate types,
4. Move the parsed and cleansed data to the final table.
To perform this there needs to be an SSIS package that can import the initial data, called the stored procedures that manipulate the data and then move it to the final table.
Figure 3: SSIS Package
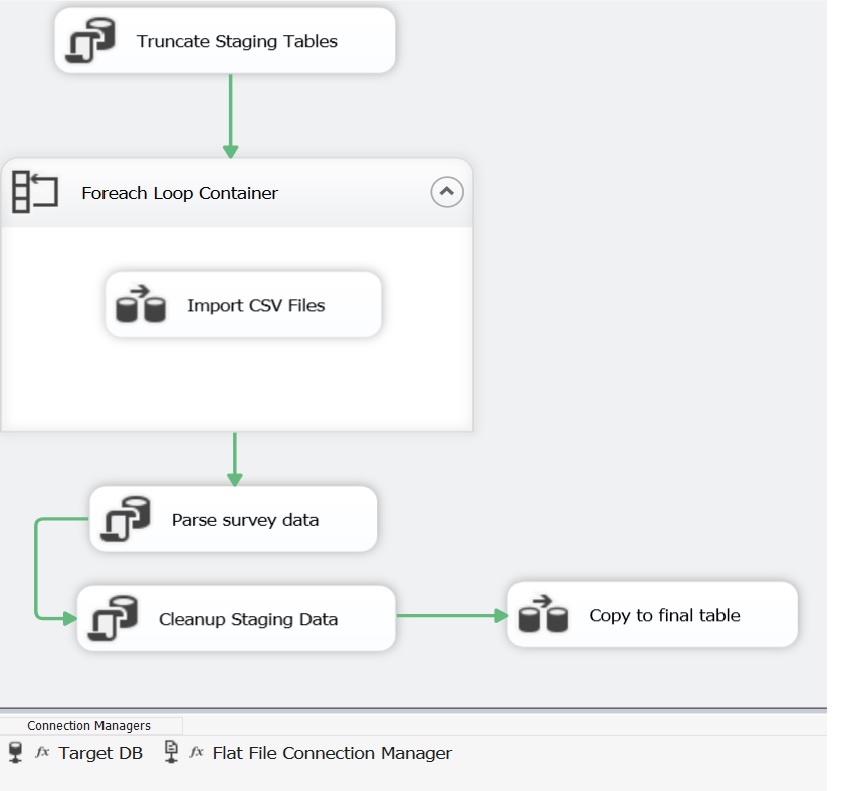
The ‘real’ work is executed within the process ‘Parse survey data’. This executes a stored procedure ‘usp_ParseSurveyData’, which uses ‘DelimetedSplit8K’ and ROW_NUMBER to extract the individual ‘fields’ from the CSV data, along with a number to identify which element they were from within that CSV data:
Listing 4: Part of the Stored Procedure that parses the CSV data
SELECT LEFT(t.ImportData, CHARINDEX(',', t.ImportData) - 1) , ----ID of the Row
s.Item ,
ROW_NUMBER() OVER ( PARTITION BY LEFT(t.ImportData, CHARINDEX(',', t.ImportData) - 1)
ORDER BY LEFT(t.ImportData, CHARINDEX(',', t.ImportData) - 1) ASC ) AS ColSequence
FROM Staging_SingleColumn AS t
CROSS APPLY dbo.DelimitedSplit8K(t.ImportData, ',') AS s;
Figure 4: Example output from Listing 4 query
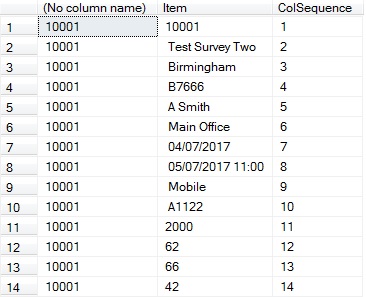
From the example shown above I now know that there are 14 elements within this row. The first 9 and 12, 13 and 14 are of known data and elements 10 and 11 are unknown data, which still needs to be stored in the final table.
Figure 5: Row stored in final table (NULL columns not displayed)

Conclusion
Personally, I like to make SSIS projects as simple as I can – with the more complex processing within the database, where I can utilise T-SQL fully. This project is an example of that, where SSIS was used to move data around and call stored procedures for the heavier work.
There are probably people out there who solved this issue in a very similar way but I couldn’t find any articles. Therefore I have produced this in case anybody else out there had the same issues.
Source Files
Download the example files

I don’t know if you can read my comment but I have a question about your example 🙂
Thanks you very much for your help
Lise
Ask your question – I’ll help if I can.