
Introduction
SQL 2016 has introduced support for JSON data. The nature of JSON data means that an indexing strategy isn’t as obvious. This article details my initial work, testing various methods for accessing the JSON data.
Background
Where I work a handful of APIs have been written for an interface, which currently log their actions to a series of text files for auditing purposes, as JSON data. This information will only be needed if problems are encountered or the actions taken by the API are called into question.
Testing has shown that when a large number of calls are made to these APIs in a short space of time issues may be encountered with accessing these text files, occasionally data might not be written to these files or an API might be blocked, because another process is also accessing the required file.
In addition, examining this data could be a tedious process – searching for particular items of JSON data in what could be very large text files.
As we will be moving to SQL Server 2016 this seemed an ideal opportunity to examine the JSON support within.
Investigations
First of all, although SQL 2016 does have support via several JSON-related commands, it doesn’t have a data type for JSON – unlike its cousin, XML. Microsoft refers to this as ‘built-in’ support as oppose to ‘native’ support and their stance on this is detailed here.
So, I’m going to use NVARCHAR(MAX) to store my JSON data.
JSON data, being what it is, can be lengthy and contain a large amount of data, the structure of which may be unknown at the time we want to query it. Because of the choice of data-type, I can use the Full text Index feature of SQL Server. This does of course have additional overheads, so I wanted to see if it was worth the effort, instead of just relying on the LIKE operator.
Test Environment
I have created a database with two tables – one has Full Text Indexing and the other does not.
Listing 1: The database and tables
CREATE DATABASE JSONIndexes; GO CREATE TABLE dbo.JSON_Data_With_FT ( ID INT IDENTITY(1, 1) NOT NULL , JSONText NVARCHAR(MAX) NOT NULL , CONSTRAINT [PK_JSON_Data_With_FT] PRIMARY KEY CLUSTERED ( [ID] ASC ) ); CREATE FULLTEXT CATALOG ft AS DEFAULT; CREATE FULLTEXT INDEX ON dbo.JSON_Data_With_FT ( JSONText ) KEY INDEX PK_JSON_Data_With_FT WITH STOPLIST = SYSTEM; CREATE TABLE dbo.JSON_Data_No_FT ( ID INT IDENTITY(1, 1) NOT NULL , JSONText NVARCHAR(MAX) NOT NULL , CONSTRAINT [PK_JSON_Data_No_FT] PRIMARY KEY CLUSTERED ( [ID] ASC ) );
Both of the tables will contain identical data.
By using Redgate’s ‘SQL Data Generator’ and a process to create JSON data from that, I’ve managed to load varying amounts of data into these two tables.
Figure 1: Example of the test data
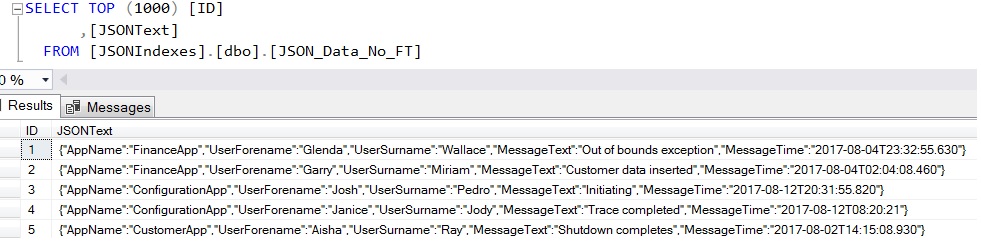
The basic JSON data
The data is quite simple – an application name, the user forename and surname, a message and a date/time stamp.
My initial tests used a very small amount of data – 20,000 rows initially.
Figure 2: Full Text index results
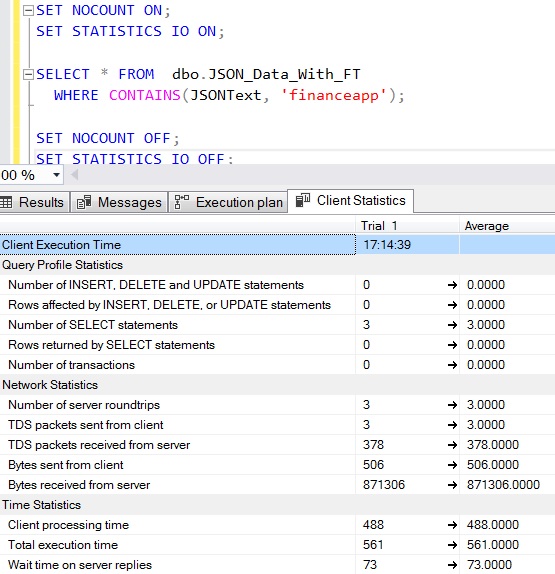
20,000 rows Full Text Index
Figure 3: LIKE operator results
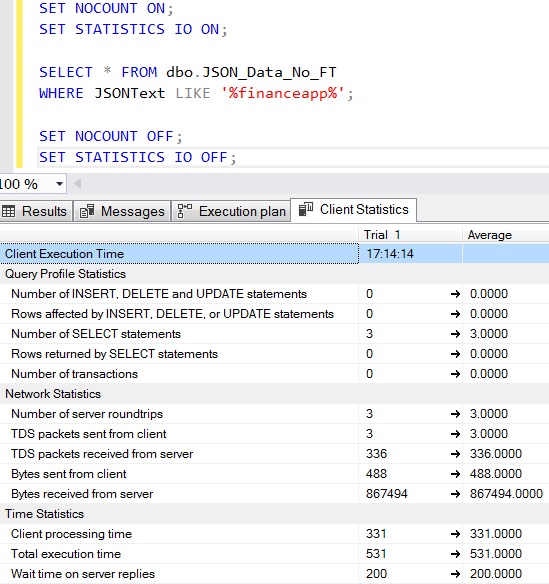
20,000 rows using LIKE
Looking at the ‘Total execution time’ it is apparent that the LIKE operator performed faster, which wasn’t what I was expecting.
The next step was to increase the amount of data.
With 200,000 rows the full text index is substantially faster than the LIKE operator. The space required for the indexes is also substantially different – 0.2MB for the table that does not have the full text index and 22.9MB for the table that does.
Figure 4: Full Text index returns data results in 11 seconds

200,000 Rows and Full text Index
Figure 5: and the LIKE operator returns the same results in 17 seconds
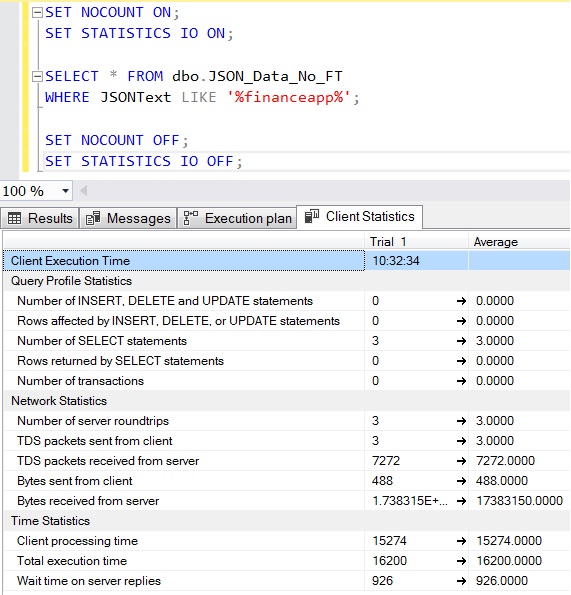
200,000 rows with LIKE
I have to say, although 11 seconds is better than 17, it isn’t exactly fast.
Non Clustered Index
So what if we add a non-clustered index to the data? Of course it would be worse than useless to apply it to the actual JSON data but a derived column, with the data that we would generally search upon might be a better alternative. In the listing below I’m going to assume that ‘AppName’ is the field of most interest, for searching purposes.
Listing 2: Add a derived column and create an index against it
ALTER TABLE dbo.JSON_Data_With_FT ADD AppName AS (JSON_VALUE([JSONText],'$.AppName')); GO CREATE NONCLUSTERED INDEX [IX_JSON_Data_FT_AppName] ON [dbo].[JSON_Data_With_FT] ( AppName ASC ) GO
When creating the index, the following warning is displayed:
Warning! The maximum key length for a nonclustered index is 1700 bytes. The index ‘IX_JSON_Data_FT_AppName’ has maximum length of 8000 bytes. For some combination of large values, the insert/update operation will fail.
As long as the value for ‘AppName’ doesn’t exceed 1700 bytes then this method will work.
Note: Creating a derived column only appears to work if the field required from within the JSON data is NOT within an array (even if it only occurs once within that array). For this testing I used the option WITHOUT_ARRAY_WRAPPER to ensure the JSON text did not have the array identifiers ‘[‘ or ‘]’ within the JSON data. If the field required is within an array an error will not be returned from the creation of the derived column but it will remain as NULL.
Adding this index has increased the index space used from 22.9MB to 31.1MB.
Figure 6: Selection with derived column index

Indexed derived column
This time the query returned in 9 seconds. Not a massive increase but still an improvement.
Conclusion
A small number of rows does not appear to warrant a Full Text index but this changes quickly with larger amounts of data. If there is a column that is generally required for searching then a derived column and an index on that will improve the efficiency of the SELECT.
